

MORe Aggregator
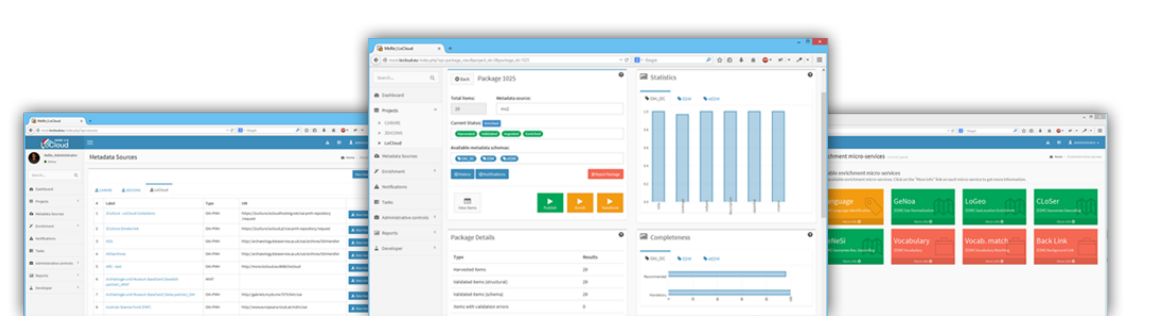
The Metadata & Object Repository (MoRe) is an easy and powerful tool to aggregate information. Harvest metadata from multiple sources in multiple schemas. Validate, clean and normalize large amounts of content. Transform into a common schema and publish to multiple targets.
Easy: No setup needed. MoRe is available as on Service on the Cloud. It’s highly intuitive UI makes aggregating information an amazingly easy job.
Flexible: MoRe provides a flexible, micro-services oriented architecture. Create your own micro-services in any programming language and integrate them into the aggregation workflow.
Scalable: It’s distributed architecture allows to scale both services and storage. Store your data in a fedora-commons repo, Apache Cassandra cluster. More storage solutions coming up soon.
Curation oriented: Take control of your data. MoRe automatic validates your content, measures quality and allows you to curate/enrich it using a variety of enrichment micro-services.
Features
- Multiple input sources: OAI-PMH 2.0, Wikimedia, Omeka, etc.
- Multiple publish targets: OAI-PMH 2.0, Archive dump, Sesame RDF Store, SolR, etc.
- Multiple schemas: DC, EDM, ESE, LIDO, EAD, CARARE, …
- Flexible workflow: Define workflows per project.
- Quality measurement: Measure completeness per package and per schema.
- Enrichment services: Plethora of ready to use enrichment services.
- Validation: Validate your metadata using flexible validation services.
- Intuitive Statistics: Detailed aggregation statistics
- Create your own services: Create your own enrichment services and integrate them easily.
…and much more!
Get more documentation on our support portal.
Discover MORe on our dedicated website: http://more.dcu.gr/
